Seeing and Modelling Humans

Gaussian Splatting Decoder for 3D-aware Generative Adversarial Networks
We present a novel approach that combines the high rendering quality of NeRF-based 3D-aware Generative Adversarial Networks with the flexibility and computational advantages of 3DGS. By training a decoder that maps implicit NeRF representations to explicit 3D Gaussian Splatting attributes, we can integrate the representational diversity and quality of 3D GANs into the ecosystem of 3D Gaussian Splatting for the first time.

Multi-view Inversion for 3D-aware Generative Adversarial Networks
We developed a method building on existing state-of-the-art 3D GAN inversion techniques to allow for consistent and simultaneous inversion of multiple views of the same subject. We employ a multi-latent extension to handle inconsistencies present in dynamic face videos to re-synthesize consistent 3D representations from the sequence.
Neural Human Modelling and Animation
We train deep neural networks on high resoution captured volumetric video data of an actor performing multiple motions in order to learn a generative model for the synthesis of new motion sequences with highly realistic shape and appearance. We use a-priori knowledge in form of a statistical human model in order to guide the learning process. Besides, explicit representations, we also explore representations like NeRF for human representation and animation.

Neural Head Modelling
We present a practical framework for the automatic creation of animatable human face models from calibrated multi-view data. Based on captured multi-view video footage, we learn a compact latent representation of facial expressions by training a variational auto-encoder on textured mesh sequences.

Neural Speech-driven Facial Animation
We have developed various speech/text-driven animation methods based on viseme input such that our avatars can be driven by either speech or text.
Video-driven Face Animation
Video-driven animation transfershe facial expression from the video of a source actor to an animatable face model or avatar. We developed a new video-driven animation approach in order to drive our neural head model based on a pre-trained expression analysis network that provides subject-independent expression information.

Deep Fake Detection and Generation
We conduct research on both the generation as well as the detection of Deepfake content. In case of the former, we focus our research on the development of novel model architectures, aiming for an increase in percieved quality and photorealism of the fakes. Moreover, we study the models generalization to arbitrary identities.

Audio-driven Gesture Synthesis
We develop new methods for audio-driven gesture synthesis based on deep neural networks to learn gesticulation skills from human demonstrations. More specifically, we train a variational auto-encoder on human pose sequences to learn a latent space of human gestures and train an additional network to learn a mapping from speech features to the latent representation of gestures.

From Volumetric Video To Animation
We present a pipeline for creating high-quality animatable volumetric video content. Key features are the supplementation of captured data with semantics and animation properties and leveraging of geometry- and video-based animation methods. We suggest a three-tiered solution: modeling low-resolution features in the geometry, overlying video-based textures to capture subtle movements, and synthesizing caomplex features using an autoencoder-based approach.
Scenes, Structure and Motion

Compact 3D Scene Representation via Self-Organizing Gaussian Grids
We introduce a compact scene representation organizing the parameters of 3D Gaussian Splatting (3DGS) into a 2D grid with local homogeneity, ensuring a drastic reduction in storage requirements without compromising visual quality during rendering.
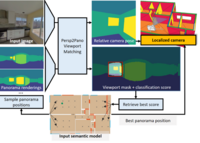
6D Camera Localization in Unseen Environments
We present SPVLoc, a global indoor localization method that accurately determines the six-dimensional (6D) camera pose of a query image and requires minimal scene-specific prior knowledge and no scene-specific training.
AI-Based Building Digitalization
We employ AI, specifically deep neural networks, to automate and streamline the manual processes involved in building digitalization. This enhances efficiency in tasks such as gathering information from diverse sources for monitoring and automation within the construction industry.

Event-Based Vision
Event cameras are novel imaging sensors that respond to local changes in brightness and send an asynchronous strame of change detections (events) per pixel. Hence, each pixel operates independently and asynchronously, leading to low latency, high dynamic range and low data. This means, that new methods have to be developed for this type of data. We develop event-based solutions to different Computer Vision problems and applications.

Tree and Plant Modeling
Image-based plant reconstruction and modeling is an important aspect of digitalization. We address the acquisition, reconstruction and image-based modeling of plants with classical Computer Vision approaches, modern AI technology and procedural methods from Computer Graphics.

Deep 6 DoF Object Detection and Tracking
The display of local assistance information in augmented reality (AR) systems to support assembly tasks requires precise object detection and registration. We present an optimized deep neural network for 6-DoF pose estimation of multiple different objects in one pass. A pixel-wise object segmentation placed in the middle part of the network provides the input to control a feature recognition module. Our pipeline combines global pose estimation with a precise local real-time registration algorithm and solely synthetic images are used for training.
Computational Imaging and Video

Video-Based Bloodflow Analysis
The extraction of heart rate and other vital parameters from video recordings of a person has attracted much attention over the last years. In our research we examine the time differences between distinct spatial regions using remote photoplethysmography (rPPG) in order to extract the blood flow path through human skin tissue in the neck and face. Our generated blood flow path visualization corresponds to the physiologically defined path in the human body.

Hyperspectral Imaging
Hyperspectral imaging records images of very many, closely spaced wavelengths, ranging from wavelengths in the ultraviolet to the long-wave infrared with applications in medicine, industrial imaging or agriculture. Reflectance characteristics can be used to derive information in the different wavelengths can be used to derive information on materials in industrial imaging, vegetation and plant health status in agriculture, or tissue characteristics in medicine. We develop capturing, calibration and data analysis techniques for HSI imaging.
Learning and Inference

Anomaly Detection and Analysis
We develop deep learning based methods for the automatic detection and analysis of anomalies in images with a limited amount of training data. For example, we are analyzing and defining different types of damages that can be present in big structures and using methods based on deep learning to detect and localize them in images taken by unmanned vehicles. Some of the problems arising in this task are the unclear definition of what constitutes a damage or its exact extension, the difficulty of obtaining quality data and labeling it, the consequent lack of abundant data for training and the great variability of appearance of the targets to be detected, including the underrepresentation of some particular types.

Deep Detection of Face Morphing Attacks
Facial recognition systems can easily be tricked such that they authenticate two different individuals with the same tampered reference image. We develop methods for fully automatic generation of this kind of tampered face images (face morphs) as well as methods to detected face morphs. Our face morph detection methods are based on semantic image content like highlights in the eyes or the shape and appearance of facial features.
Read more
Augmented and Mixed Reality

Event-based Structured Light for Spatial AR
We present a method to estimate depth with a stereo system of a small laser projector and an event camera. We achieve real-time performance on a laptop CPU for spatial AR.
Tracking for Projector-Camera Systems
We enable dynamic projection mapping on 3d objects to augment envrinments with interactive additional information. Our method establishes a distortion free projection by first analyzing and then correcting the distortion of the projection in a closed loop. For this purpose, an optical flow-based model is extended to the geometry of a projector-camera unit. Adaptive edge images arer used in order to reach a high invariande to illumination changes.
Older Research Projects

Texture Based Facial Animation/Re-Targeting
Generating photorealistic facial animations is still a challenging task in computer graphics. We developed methods that combine high quality textures and approximate geometric models to achieve the high visual quality of image based methods while still retaining the flexibility of computer graphics models to allow for rigid transforms and deformation.

Deep 3D Trajectories of Vehicles
We develop advanced deep learning based approaches for the estimation of 3D pose and trajectories of vehicles for vehicle behaviour prediction. In our research, we address several challenges, e.g. 3D estimation from monocular images with scarce training data under different viewing angles. In particular, one specific goal is to monitor the traffic through a network of cameras communicating with a central node, which is in charge of analyzing the trajectories of the traffic participants in order to predict dangerous situations and warn the involved individuals about the imminent danger.

Portrait Relighting
We develop a model-based deep learning approaches for portrait image relighting. Specifically, we incorporate model-based knowledge into well established networks for image manipulation in order to guide the relighting process but also to account forinaccuracies in the training data. This includes a multiplicative image formation model of shading allowing to add smoothness constraint and inversion as well as motion compensation.
Read more

Hybrid Facial Capture and Animation
High quality capture, tracking and animation of human faces is a challenging task. We are developing new models that do not follow the 'one fits all' paradigm. Instead we use non-/linear models to describe facial geometry (identity) and deformation (expression). Additionally, image based rendering techniques are used to model complex regions like eyes, mouth and lips.

Modeling and Capturing 3D Shape and Motion of Humans
We generate realistic animatable 3D representations of captured humans from sparse 3D recosntructions. Our model is based on a combination of Linear Blend Skinning and Dual Unit Quaternion Blending and allows to accurately resemble captured subjects in shape and motion. The separation of shape and motion supports a variety of automatic applications, e.g. individualized avatar creation, retargeting as well as direct animation of scan data.
Sparse Tracking of Deformable Objects
Finding reliable and well distributed keypoint correspondences between images of non-static scenes is an important task in Computer Vision. We present an iterative algorithm that improves a descriptor based matching result by enforcing local smoothness. The optimization results in a decrease of incorrect correspondences and a significant increase in the total number of matches. The runtime of the overall algorithm is by far dictated by the descriptor based matching.

Pose-Space Image-based Rendering
Achieving real photorealism by physically simulating material properties and illumination is still computationally demanding and extremely difficult. Instead of relying on physical simulation, we follow a different approach for photo-realistic animation of complex objects, which we call Pose-Space Image-Based Rendering (PS-IBR). Our approach uses images as appearance examples to guide complex animation processes, thereby combining the photorealism of images with the ability to animate or modify an object.

Surface Tracking and Interaction in Texture Space
We present a novel approach for assessing and interacting with surface tracking algorithms targeting video manipulation in postproduction. As tracking inaccuracies are unavoidable, we enable the user to provide small hints to the algorithms instead of correcting erroneous results afterwards. Based on 2D mesh warp-based optical flow estimation, we visualize results and provide tools for user feedback in a consistent reference system, texture space. In this space, accurate tracking results are reflected by static appearance, and errors can easily be spotted as apparent intensity change, making user interaction for tracking improvement results more intuitive.

Reflection Analysis for Face Morphing Attack Detection
For the detection of morphed face images, we study the effects of the generation of such morphs on the physical correctness of the illumination. Morphed face images do often contain implausible highlights, due to different face geometries and lighting situations in the original images. In fact, shape and position of the highlights do not fit to the geometry of the face and/or illumination settings.

Non-Rigid Structure-from-Motion
Reconstructing the 3D shape of a deformable object from a monocular image sequence is a challenging task. We address the problem of reconstructing volumetric non-rigid 3D geometries under full perspective projection by employing a 3D template model of the object in rest pose.

Joint Tracking and Deblurring
Video tracking is an important task in many automated or semi-automated applications, like cinematic post production, surveillance or traffic monitoring. Most established video tracking methods fail or lead to quite inaccurate estimates when motion blur occurs in the video, as they assume that the object appears constantly sharp in the video. We developed a novel motion blur aware tracking method that estimates the continuous motion of a rigid 3-D object with known geometry in a monocular video as well as the sharp object texture.

High-Resolution 3D Reconstruction
We developed a binocular stereo method which is optimized for reconstructing surface detail and exploits the high image resolutions of current digital cameras. Our method occupies a middle ground between stereo algorithms focused at depth layering of cluttered scenes and multi-view ”object reconstruction” approaches which require a higher view count. It is based on global non-linear optimization of continuous scene depth rather than discrete pixel disparities. We use a mesh-based data-term for large images, and a smoothness term using robust error norms to allow detailed surface geometry.

Shape from Texture
We present a shape-from-texture SFT formulation, which is equivalent to a single-plane/multiple-view pose estimation problem statement under perspective projection. As in the classical SFT setting, we assume that the texture is constructed of one or more repeating texture elements, called texels, and assume that these texels are small enough such that they can be modeled as planar patches. In contrast to the classical setting, we do not assume that a fronto-parallel view of the texture element is known a priori. Instead, we formulate the SFT problem akin to a Structure-from-Motion (SFM) problem, given n views of the same planar texture patch.

Reconstruction and Rendering of the Human Head
We are developing algorithms for reconstructing the human head in high detail from calibrated images. Our method is passive, i.e. we do not use projected patterns (as, for example, structured light approaches do) and we don’t use photometric normals. We are interested in recovering not only fine details in the face but also the appearance and some geometric detail of the subject’s hair, thereby capturing the complete human head. This is challenging due to the intricate geometry of hair and its complex interaction with light.

Near Regular Texture Analysis for Image-Based Texture Overlay
Image-based texture overlay or retexturing is the process of augmenting a surface in an image or a video sequence with a new, synthetic texture. On the one hand, texture distortion caused by projecting the surface into the image plane should be preserved. On the other hand, only the texture albedo should be altered but shading and reflection properties should remain as in the original image. In many applications, such as augmented reality applications for virtual clothing, the surface material to be retextured is cloth. In this case, high frequency details, representing e.g. selfshadowing of the yarn structure, might also be a property that should be preserved in the augmented result.

Near Regular Texture Synthesis
We developed a method to synthesize near-regular textures in a constrained random sampling approach. We treat the texture as regular and analyze the global regular structure of the input sample texture to estimate two translation vectors defining the size and shape of a texture tile. In a subsequent synthesis step, this structure is exploited to guide or constrain a random sampling process so that random samples of the input are introduced into the output preserving the regular structure previously detected. This ensures the stochastic nature of the irregularities in the output yet preserving the regular pattern of the input texture.

Virtual Clothing
We developed a virtual mirror prototype for clothes that uses a dynamic texture overlay method to change the color and a printed logo on a shirt while a user stands in front of the system wearing a prototype shirt with a (line)-pattern. Similar to looking into a mirror when trying on clothes, the same impression is created but for virtually textured garments. The mirror is replaced by a large display that shows the mirrored camera image, for example, the upper portion of a person's body.

Virtual Shoes
We have developed a Virtual Mirror for the real-time visualization of customized sports shoes. Similar to looking into a mirror when trying on new shoes in a shop, we create the same impression but for virtual shoes that the customer can design individually. For that purpose, we replace the real mirror by a large display that shows the mirrored input of a camera capturing the legs and shoes of a person. 3-D real-time tracking of both feet and exchanging the real shoes by computer graphics models gives the impression of actually wearing the virtual shoes.

Joint Estimation of Deformation and Shading for Dynamic Texture Overlay
We developed a dynamic texture overlay method to augment non-rigid surfaces in single-view video. We are particularly interested in retexturing non-rigid surfaces, whose deformations are difficult to describe, such as the movement of cloth. Our approach to augment a piece of cloth in a real video sequence is completely image-based and does not require any 3-dimensional reconstruction of the cloth surface, as we are rather interested in convincing visualization than in accurate reconstruction.

Efficient Video Streaming for Highly Interactive 3D Applications
Remote visualization of interactive 3D applications with high quality and low delay is a long-standing goal. One approach to enable the ubiquitous usage of 3D graphics applications also on computational weak end devices is to execute the application on a server and to transmit the audio-visual output as a video stream to the client. In contrast to video broadcast, interactive applications like computer games require extremely low delay in the end to end transmission. In this work, we use an enhanced H.264 video codec for efficient and low delay video streaming. Since the computational demanding video encoding is executed in parallel to the application, several optimizations have been developed to reduce the computational load by exploiting the 3D rendering context.

Semi-Automated Segmentation of Human Head Portraits
In this project, a system for the semi-automated segmentation of frontal human head portraits from arbitrary unknown backgrounds has been developed. The first fully automated processing stage computes an initial segmentation by combining face feature information with image-deduced color models and a learned parametric head shape model. Precise corrections may then be applied by the user with minimum effort in an interactive refinement step.

Image-based Rendering of Faces
In this work, image-interpolation from previous views of a video sequence is exploited in order to realistically render human heads including hair. A 3D model-based head tracker analyzes human motion and video frames showing different head poses are subsequentially stored in a database. New views are rendered by interpolating from frames in the database which show a similar pose. Remaining errors are corrected by warping with a approximate 3D model. The same model is exploited to warp the eye and mouth region of the current camera frame in order to show facial expressions.

3D Reconstruction from Turntable Sequences
A method for the enhancement of geometry accuracy in shape-from-silhouette frameworks is presented. For the particular case of turntable scenarios, an optimization scheme has been developed that minimizes silhouette deviations which correspond to shape errors. Experiments have shown that the silhouette error can be reduced by a factor of more than 10 even after an already quite accurate camera calibration step. The quality of an additional texture mapping can also be drastically improved making the proposed scheme applicable as a preprocessing step in many different 3-D multimedia applications.

Facial Expression Analysis from Monocular Video
A 3D model-based approach for the estimation of facial expressions from monocular video is presented. The deformable motion in the face is estimated using the optical flow constraint in a hierarchical analysis-by-synthesis framework. A generic face model parameterized by facial animation parameters according to the MPEG-4 standard constrains the motion in the video sequences. Additionally, illumination is estimated to robustly deal with illumination changes. The estimated expression parameters can be applied to other model to allow for expression cloning of face morphing.