The inner workings of modern AI models are highly complex and consist of thousands of components that interact with each other. Understanding the role of each of these components (e.g., neurons) is critical and necessary to ensure security, transparency, and compliance with the latest regulations, such as the EU AI Act, in safety-critical applications.
With SemanticLens, we introduce a universal explanation method for neural networks that allows for a systematic understanding and validation of network components [1]. By mapping the hidden knowledge encoded by components into a semantically structured space, unique operations become possible, including Search (search engine-type queries for encoded knowledge, answering questions such as “Does the network know that a blue-whitish veil is associated with melanoma?”), Describe (systematic analysis of components including automated labeling and functional role explanations, addressing “What and how is the model using its knowledge?”), Compare (“How do learned concepts compare across different model architectures or layers?”), Audit (validate decision-making capabilities against requirements to identify “Which relevant concepts align or misalign with expectations?”), and Evaluate Interpretability (“How human-interpretable is each component, and how can interpretability be improved?”).
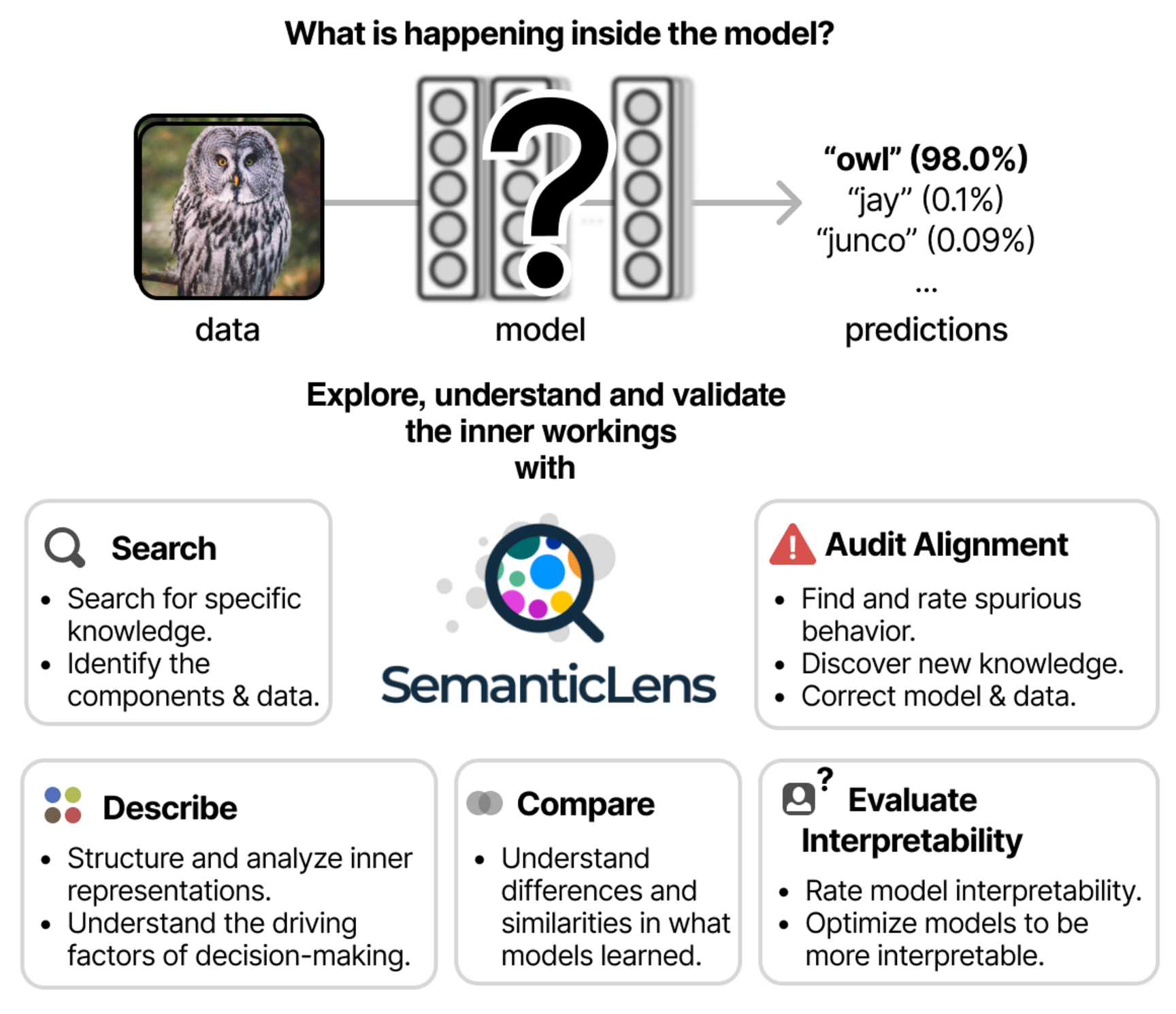
Fully scalable and operating with minimal human input, SemanticLens is effective for debugging and validation, summarizing model knowledge, aligning reasoning with expectations (e.g., adherence to the ABCDE-rule in melanoma classification), and detecting components tied to spurious correlations and their associated training data.
SemanticLens embeds the hidden knowledge encoded by individual components of an AI model into the semantically structured, multi-modal space of a foundation model such as CLIP, as illustrated in the figure below.
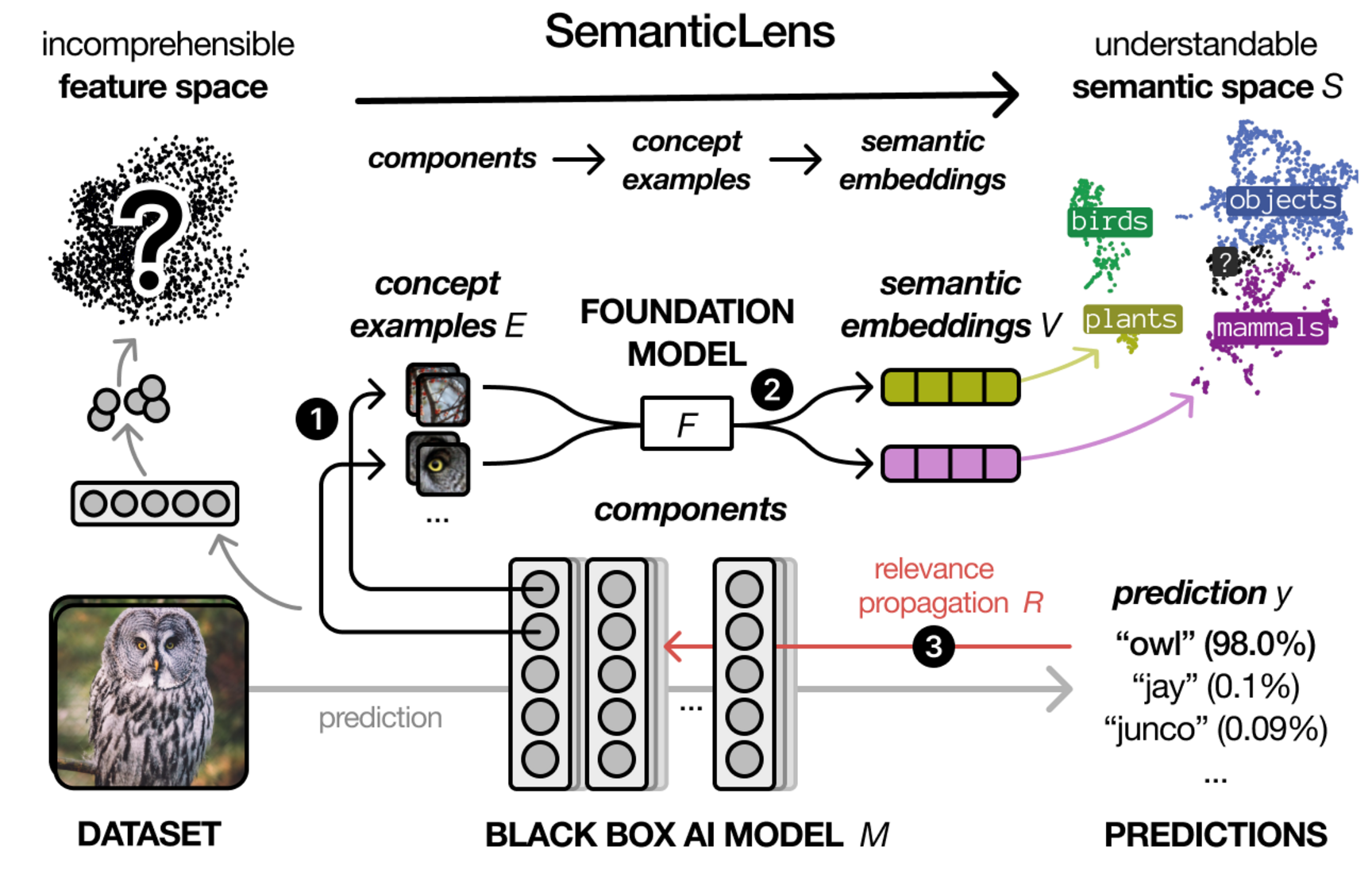
This semantic model embedding is realized by two mappings:
- Components → concept examples: For each component (e.g., neuron) of a model M, we collect a set of examples E (e.g., highly activating image patches) representing the concepts encoded by this component.
-
Concept examples → semantic space: We embed each set of concept examples E into the semantic space S of a multimodal foundation model F such as CLIP. As a result, each single component of model M is represented by a vector.
In addition, we use CRP [2] to identify relevant components and circuits for an individual model prediction, forming a third mapping:
- Prediction → components: Relevance scores R quantify the contributions of model components to individual predictions y.
By mutually connecting the model representation (M), the relevant (training) data (E), the semantic interpretation (F), and the model prediction (y), SemanticLens offers a holistic approach, which enables one to systematically analyze the internals of AI models and their prediction behaviors in a scalable manner. The core functionalities of SemanticLens are:
- Search: Efficiently search via text prompts or other data modalities to identify encoded knowledge, pinpointing relevant components and data samples. For instance, querying a vision model for concepts like “skin color“ or “watermark“ can uncover elements potentially linked to fairness concerns or data quality issues, respectively.
- Describe: Explore and analyze at scale what concepts the model has learned (with textual labels), which concepts deviate from expectation (e.g., are missing or unrelated), and how the model is using its knowledge for predictions.
- Compare: Compare learned concepts qualitatively and quantitatively across models, varying architectures, or training procedures. Comparisons allow, e.g., to understand and track how representations and their encoded knowledge change under continuous learning scenarios.
- Audit alignment: Evaluate and compare the alignment of the model’s encoded knowledge with expected human-defined concepts. As such, it is possible to understand which concepts are validly, spuriously, or unexpectedly learned and used by a model. SemanticLens further allows to identify the corresponding components and data samples, which can subsequently be used to reduce unwanted feature reliance (e.g., via pruning or data cleaning).
- Evaluate human interpretability: Rate and compare how human-interpretable the concepts encoded by the hidden network components are in terms of “clarity”, “polysemanticity”, and “redundancy”. Easy to compute measures allow to optimize models to be more interpretable in scale without the need for costly user studies.
Ultimately, the transformation of the model into a semantic representation, which not only reveals what and where knowledge is encoded but also connects it to the (training) data and decision-making, enables systematic component-level validation and opens up new possibilities for more robust and trustworthy AI.
Try SemanticLens yourself:
An interactive live demo of the search, describe and evaluation capabilities of SemanticLens is available here, developed and supervised by Oleg Hein.

References
| [1] | Maximilian Dreyer, Jim Berend, Tobias Labarta, Johanna Vielhaben, Thomas Wiegand, Sebastian Lapuschkin, and Wojciech Samek. “Mechanistic understanding and validation of large AI models with SemanticLens”. In: Nature Machine Intelligence (Aug. 14, 2025). ISSN: 2522-5839. DOI: 10.1038/s42256-025-01084-w. |
| [2] | Reduan Achtibat, Maximilian Dreyer, Ilona Eisenbraun, Sebastian Bosse, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. “From attribution maps to human-understandable explanations through Concept Relevance Propagation”. In: Nature Machine Intelligence 5.9 (Sept. 1, 2023), pp. 1006–1019. ISSN: 2522-5839. DOI: 10.1038/s42256-023-00711-8. |